Otimização de Algoritmos · Redis
Leetcode na vida real
Encontrando, isolando e resolvendo um desafio de algoritmo em uma aplicação real.
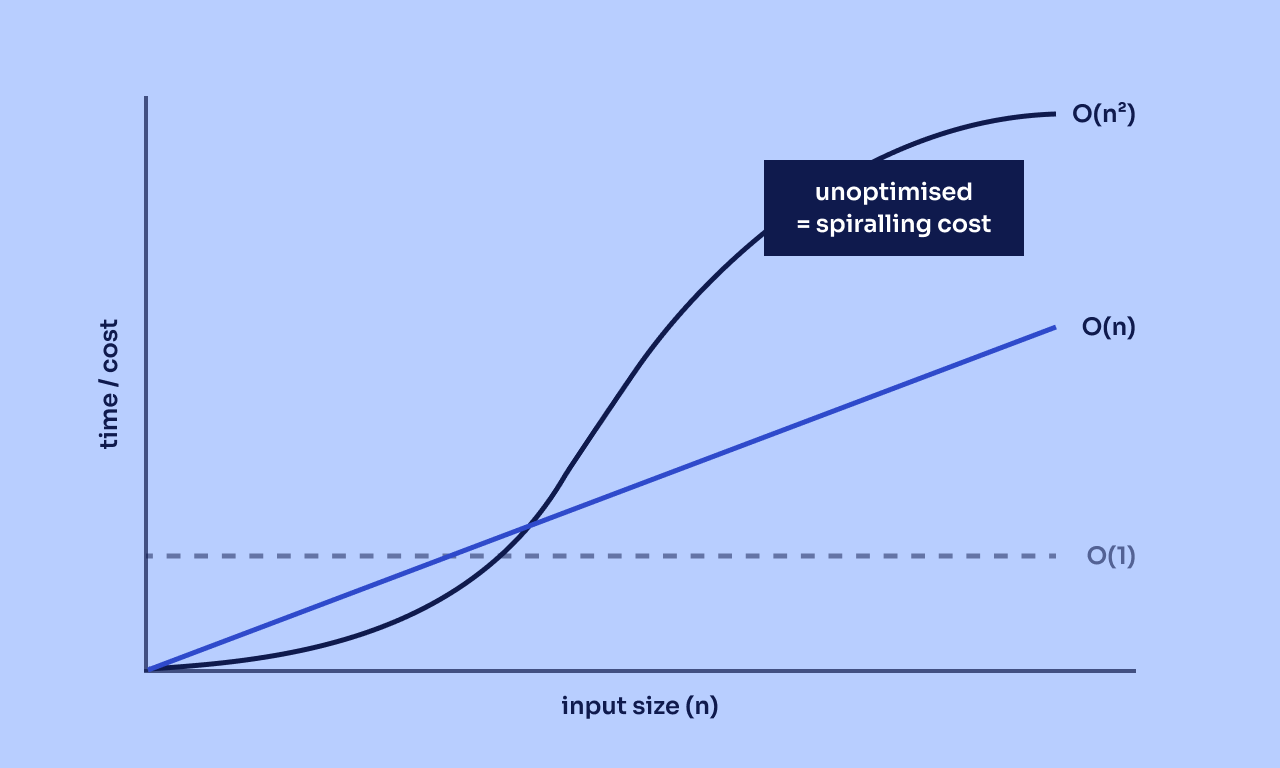
Introdução
Um cliente relatou que a exclusão em lote do cache Redis estava muito lenta. Embora inicialmente se assumisse que o Redis era o culpado, descobriu-se que o algoritmo da aplicação era o responsável. Esta é a abordagem sistemática que nossa equipe seguiu para encontrar, isolar e resolver o desafio de performance.
Debugging Inicial — Caçando Gargalos

Antes do profiling, hipóteses iniciais foram formadas sobre possíveis gargalos. No entanto, o real valor estava em confirmar cientificamente essas suspeitas com um profiler, identificando onde a maior parte do tempo de processamento era gasta e aplicando correções direcionadas.
Neste caso, o profiling mostrou que a exclusão no Redis levou apenas 5 segundos dos 4 minutos totais de tempo de resposta, indicando a necessidade de investigar mais profundamente a lógica da aplicação.
Profiling
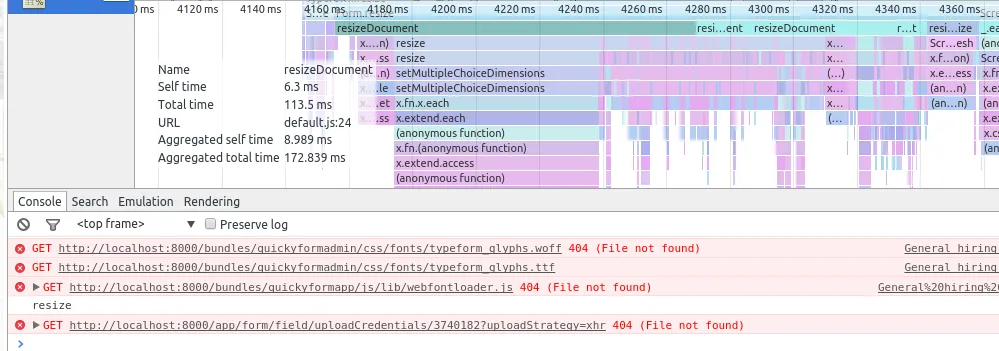
Usando o profiler, ficou claro que uma função era responsável por mais de 90% do tempo gasto durante o processamento.
- Método 1: 90% do tempo de processamento
- Método 2: 3% do tempo de processamento
- Método 3: 3% do tempo de processamento
- Método 4: 3% do tempo de processamento
O Gargalo

O papel do método destacado era remover chaves de uma lista de strings com base no fato de elas começarem com algum dos prefixos de outra coleção.
Por exemplo, dadas as chaves: a, ab, abc, abcd, bcd, bcdf, bdcf
E prefixos a remover: "ab", "bcdf"
Após a filtragem, apenas "a" e "bdcf" permanecem.

O desafio era que para cada chave, o código percorria todos os prefixos, resultando em complexidade O(chaves × prefixos). Com 34.000 chaves e 27.000 prefixos, isso equivalia a 917.000.000 iterações — uma carga computacional pesada.
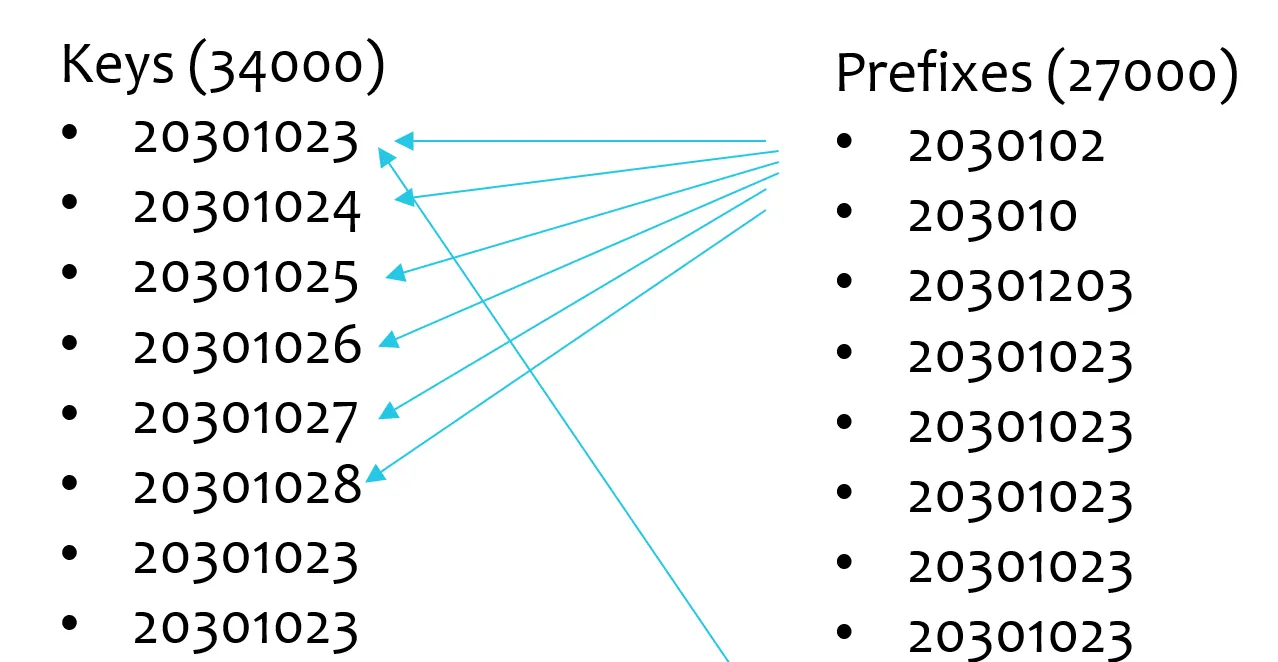
Complexidade do Algoritmo:
O(34.000 × 27.000) = 917.000.000 iterações
Solução do Algoritmo
Tipicamente, desafios como remover múltiplas chaves de um array podem ser resolvidos com hashsets ou dicionários, que têm tempo de exclusão O(1). Infelizmente, como o problema era sobre prefixos e não correspondências exatas, essa não era uma solução direta.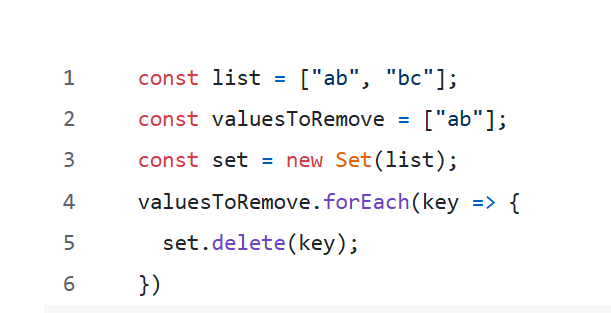
Após conduzir uma análise completa e esboçar diferentes abordagens no quadro branco, nossa equipe desenvolveu uma estratégia de indexação viável usando uma estrutura de árvore.
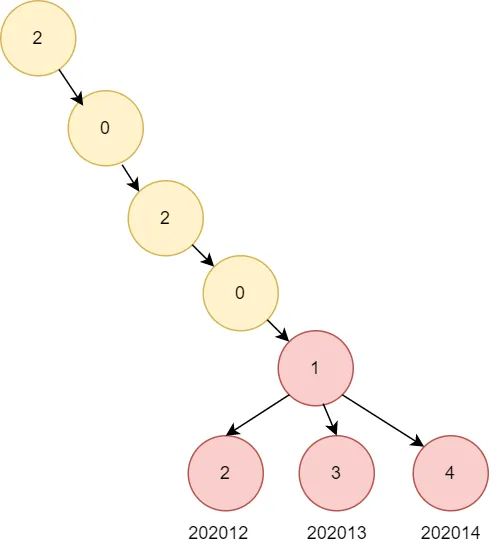
Para ilustração, considere um conjunto de chaves como: 202012, 202013, 202014
E prefixos a remover: 20201
Criamos uma árvore baseada em cada letra das chaves. Ao verificar se uma chave começa com um determinado prefixo, o algoritmo percorre a árvore até o nó final correspondente ao prefixo. Em seguida, remove o nó e todos os seus nós filhos.
Melhoria de Performance:
- Antes: O(chaves × prefixos) = 917.000.000 iterações
- Depois: O(chaves + prefixos) = 61.000 iterações
- Melhoria: De complexidade exponencial para linear
Resultados
Antes, o tempo de resposta levava 1,8 minutos para todo o endpoint; após essa mudança, foi para 6 segundos. É uma diferença massiva na eficiência do algoritmo. Além disso, efetivamente converte de exponencial para linear: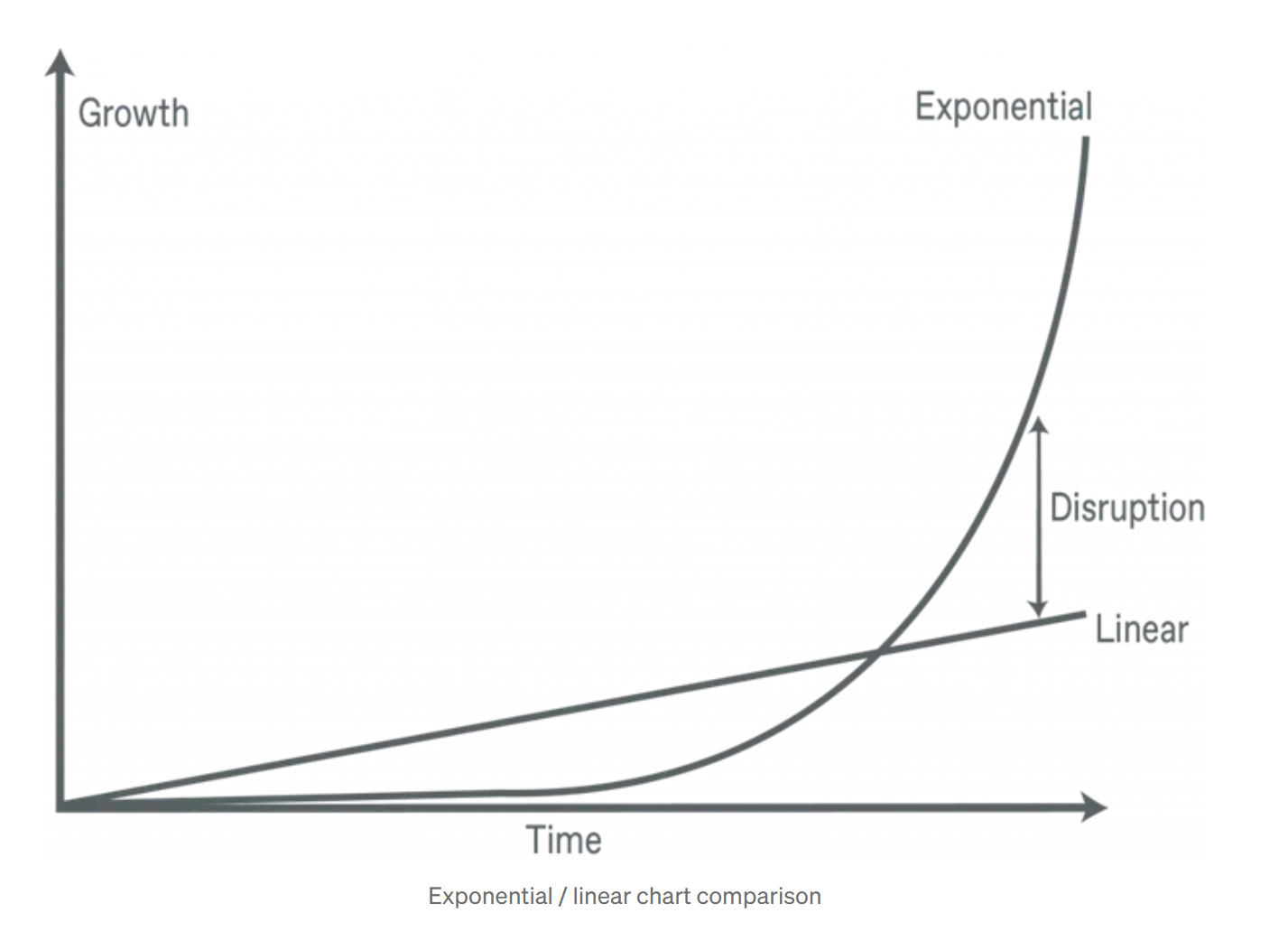
"Os testes validaram a melhoria: a abordagem inicial levou 12,2 segundos, enquanto a solução baseada em árvore rodou em apenas 65 milissegundos."
Principais Aprendizados:
- Use profiling científico para identificar o gargalo real
- Prática e familiaridade com algoritmos preparam você para desafios como este
- Entender notação Big O ajuda a identificar rapidamente padrões ineficientes
- Indexação baseada em árvore pode transformar problemas exponenciais em lineares
- Não assuma o culpado óbvio - Redis não era o problema, o algoritmo era
Resultados Finais:
Tempo de resposta: 1,8 minutos → 6 segundos (melhoria de 95%)
Execução do algoritmo: 12,2 segundos → 65 milissegundos (melhoria de 99,5%)
Este projeto demonstrou como transformar um problema exponencial em linear por meio da reestruturação algorítmica pode entregar resultados excepcionais de performance para aplicações do mundo real.